We invite you to explore the posters of the DARIAH Annual Event below. Once you click on a poster, you can zoom in by clicking on the arrows symbol at the top right corner. The url in your browser’s address bar indicates the unique link to the poster, in case you would like to tweet or share it. At the end of the page, you will find the posters abstracts and the pdf links for you to download. Remember that you can only vote once.


















Demo

Read the abstracts and download the posters here
CLARIAH-DE brings together the data, tools and services of the two research infrastructure initiatives CLARIN-D and DARIAH-DE and the existing communities of users and providers of the infrastructures until 2021.
CLARIN-D and DARIAH-DE can partly be seen as German equivalent of the European research infrastructure initiatives CLARIN and DARIAH. Potential users being aware of CLARIN and DARIAH, particularly users outside of the in-group, often wonder about the differences between both infrastructures and services. Most potential users want to access services and resources in the most convenient way, preferably with a single point of access, and want to use the services and resources they need, independent of their origin and also in combination. CLARIAH-DE also intends to open up resources for other communities and to extend its user base.
During the merger process, CLARIAH-DE faces challenges at several levels:
- (Technical level) Different approaches towards architecture, standards and services have to be considered. A merge or complementary use is not a realistic goal with look at all resources. On a technical level, different systems and rules of participation were part of the initiatives, for example with certification processes of data and service providers.
- (Communication level) Both infrastructures have developed different cultures of providing resources and of communicating with their users. For instance, dissemination and training have to be synchronized.
- (User level) The established userbase may benefit of the merger but need to become aware of the options which aligns with the need to extend the user base.
One of the most delicate assets that has to be considered is merging the processes. This includes the process of accepting data, tools and services as part of the merged infrastructure, but also the processes in the governance structures. It also touches on the trust that the users have in the research infrastructures and that should ideally be transferred to CLARIAH-DE. For this end, we will address various aspects through our work in the project:
- Besides a lean project governance, five work packages have been designed, each lead by a tandem of partners from both originating infrastructures. Each work item was designed with the requirement that both infrastructures would be contributing and that the result would provide added value to the existing users of each underlying service.
- The WPs also provide a platform for discussions on data formats, technical infrastructure, integration of major tools, training and teaching integration, and dissemination.
After a year of collaborative work in CLARIAH-DE and also due to proceeding coordination efforts between CLARIN-D and DARIAH-DE, we have achieved first results: we were able to develop a common language and an understanding of the respective other infrastructure. The partners from different contexts have been successful in establishing a productive working groups. The integration of basic infrastructures is headed in the right direction. A first joint website is available and in the future becoming a single point of access to the data, tools, and services provided originally by the two infrastructures.
* : Corresponding author
John Unsworth (2000) proposed a tentative list of scholarly primitives, and although he made a reservation that it was not meant to be exhaustive, one omission is striking, namely the exclusion of communicating. It is even more visible once one realises that all the examples he actually provides in the paper - comparing IBabble), linking (Blake Archive), or sampling (VRML visualisation of Dante's Inferno) - have the indispensable communication component.
The aim of this presentation is two-fold. First of all, we will reclaim the role of communication as one of the fundamental functional primitives, crucial in all stages of the research workflow. To use Unsworth's nomenclature, communication takes advantage of the additive characteristics of scholarly primitives and enters into combinations with all other scholarly primitives. Secondly, right after reestablishing the communication as a scholarly primitive we will swiftly proceed to problematise the notion of its universality for all disciplines through the exploration of the specificity of scholarly communication in the humanities. We will achieve that using New Panorama of Polish Literature (NPLP.pl) as a case study and the relevant, discipline-specific digital infrastructure for scholarly communication in the humanities.
It has long been suggested that communication should be seen as a fundamental element of the research workflow, rather than an activity running somewhat separate to the research practice (Latour and Woolgar 1986; Garvey 1979; Galison and Galison 1997; Nielsen 2011). Recently this idea was reinforced by Hillyer et al. (2017) who describe open science as “opening of the entire research cycle” and include communication as one of its key elements. It means that dissemination is no longer perceived as the final stage of a research process but becomes an integral part of all scholarly activities. New digital methods and tools (Dallas et al. 2017), including electronic communication and social media (Kjellberg 2010), facilitate this process. allowing scholars to communicate and collaborate with each other and the wider audience quickly and efficiently at all stages of their work. This also includes intermediary results of the work, including raw and secondary data (Castelli, Manghi, and Thanos 2013).
The incorporation of communication into all stages of the research workflow also means that choosing a certain communication strategy is obviously influenced by the perceived goal, but also this very goal has an impact other phases of the research process (e.g. collecting, sampling or linking practices). This feedback loop will be discussed in greater detail on the example of NPLP, a research infrastructure for literary scholars, which enables the creation of extended, multimedia monographs. The scholarly arguments are presented through linking text with image, visualisation, map and video content. Yet, the very act of creating a new digital collection also forces researchers to rethink how their work is presented, categorised and displayed. For instance in "Postmodern Sienkiewicz" collection (http://nplp.pl/en/kolekcja/postmodern-sienkiewicz/) authors divided their articles into shorter fragments with additional iconography allowing for non-linear reading and access through image-interface. These activities required additional work on the stage of data collection, analysis and interpretation.
In conclusion, we will tackle upon the question to what extent such communication practices are universal for all sciences and what could be treated as reserved for the humanities in the spirit of Diltheyan distinction between explaining (in sciences) and understanding (in the humanities).
* : Corresponding author
The proposed poster will present activities of the “Bibliographical Data” Working Group. The WG was established within the DARIAH consortium in 2019 and operates under VCC3: Scholarly Content Management. The main goal of the Working Group is to serve as a platform for knowledge exchange, and foster cooperation between those who work with bibliographical data: data creators, scholars interested in data-driven research, theorists of bibliography and documentation, IT specialists and other related stakeholders.
Bibliographical Data Working Group focuses on the various aspects of bibliographical data life cycle and covers the wide scope of the themes related to bibliodata. In particular, the Working Group activities concentrate on the following issues:
- Data curation
- Data quality management
- Data preparation for advanced research
- Facilitating international data-based cooperation
- Methodological issues
- Publishing bibliographies
- Processing bibliographical metadata
- Remediation of bibliographical information
- Development of user-oriented services
Activities in 2019:
After the preparatory phase, the first kick-off meeting with cca 20 attendees was organised during DARIAH Annual Event in May 2019 in Warsaw. Subsequently, the official approval for Working Group establishment was sent to DARIAH Management in July 2019. The second in-person meeting took place during DH2019 conference in Utrecht.
As the main task for the WG in 2019 and 2020 WG members have identified the preparation of the bibliographical data landscape analysis in the humanities.
Working group was formally accepted by the DARIAH management in September 2019.
Currently the Bibliographical Data Working Group consists of around 30 members from cca 15 European countries. Its activities can be followed mainly via the WG Twitter account (https://twitter.com/bibliodataWG).
Plans for 2020:
The main task for the WG is the preparation of the landscape analysis of bibliodata in the humanities.
The analysis will be centered around the following topics: bibliodata curation, bibliodata research, bibliodata tools, and bibliodata collaboration. Each of these parts will briefly analyse different aspects of bibliodata landscape, and the conclusions shall facilitate cooperation between scholars working with bibliodata, and become a basis for the future WG activities. We would love to use the occasion of the DARIAH Annual Event in Zagreb to present first results of our analysis.
Other planned activities:
- Developing relations with other DARIAH-ERIC WGs,
- Fostering opportunities for bilateral or multilateral projects of the WG members,
- Working towards integration of literary bibliodata (special poster is planned for DARIAH Event 2020)
- Promotion of the WG and bibliodata in academia via conference presentations, specialized workshops, tutorials, etc. (special workshop is planned for DARIAH Event 2020),
- Obtaining funding for the WG projects.
* : Corresponding author
Surveying the information needs of users is already a key issue in the preparatory phase of the research infrastructures. In this phase the integration of research platforms is being prepared. A research of information requirements of digital scholars is not limited only by the difficulty of reaching users, but also because of the lack of transparent platform architecture, log data cannot be used effectively. Users of platforms are often happy to get access to data and resources relevant to their research. They consider most of their work to be abstract, intellectual, or simply of such nature that computer and information technology cannot help them. Thus, many needs are not transformed into requirements, nor are they perceived as needs. In order to identify the unconscious demands of users and to find the potential for improving the research platform, we decided to make a sense-making analysis of six researchers who use the Digital library of Arne Novák in their research. Digital library of Arne Novák is a research platform providing access to the work of a prominent figure in Czech literary science, that we want to make available to the LINDAT/CLARIAH-CZ research infrastructure. A micro time-line interview was conducted with all researchers to understand how researchers use research platform, how they interact and practice research with digital data and how we can shape a vision of augmentation of human intellectual possibilities when working with this platform. The research verified that in this way we can identify unnamed and unspecified information requirements of research data users.
1 : Université de Strabourg (UMR 7044)
ArkeoGIS is a multidisciplinary application. The databases come from different sources: institutional researchers' work, graduate students' researches, private companies and archaeological heritage management services. They also come from palaeoenvironementalists', geographers' and historians' work. Multidisciplinarity is spurred and promoted All these shared databases are available and can be queried through the webGIS by ArkeoGIS' users.
Each user have its own personal and customizable project interface. One can query online all or only a part of these databases, display the results on multiple backgrounds maps, save and export them towards other tools one might use (CSV export).
Actually in release 4.2 the poster will present the latest evolutions of the tool (multichronology and shape display), and encourage users to create new communities using the platform but also discuss how the scholarly primitives evolve with digital tools.
What is ArkeoGIS ?
ArkeoGIS enables to pool and query – thanks to a mapping interface – the spatialized scientific data about the past (archaeology, environment...). ArkeoGIS is an online platform accessible in four languages (German, English, Spanish and French).
ArkeoGIS is a multidisciplinary application. The databases come from different sources: institutional researchers' work (either personal or contractual researches), graduate students' researches, private companies and archaeological heritage management services. They also come from palaeoenvironementalists', geographers' and historians' work. Multidisciplinarity is spurred and promoted All these shared databases are available and can be queried online by ArkeoGIS' users.
Each user have its own personal and customizable project interface. One can query online all or only a part of these databases, display the results on multiple backgrounds maps, save and export them towards other tools one might use (CSV export).
The chronological frame of the tool is now both customizable and multiple. ArkeoGIS' multi-chronologies system enables to aggregate, for different areas, information from the Prehistory to the Present. About ten chronologies are already available, from the Iberian Peninsula and the Mediterranean to the Middle East or continental Europe. ArkeoGIS' geographical frame enables to display information about all of these regions. As today, the most documented areas are the Upper Rhine Valley, the Mediterranean and the Middle East.
ArkeoGIS can be used for many different forms of research, individual or collective. It allows, among other things, to handle the data management plan (DMP) for contractual researches. ArkeoGIS is a powerful tool to use during different kind of studies (excavations, synthesis or PhD thesis, etc.).
Several tens of thousands of sites, objects and analysis are already available. ArkeoGIS is also linking several digital tools, allowing its users to be aware of their existence.
Every author submitting his localized data into ArkeoGIS keeps the control over them and is the only one who can amend them. Any user can easily access to other contributors' data and improve its own database. A directory allows researchers to contact each other. This initiative helps to develop scientific exchanges between countries and institutions.
The project Echo from the War started in 2008 by two graduate students (Konstantin Golev and Marian Gyaurski) with the aim to collect oral history interviews Bulgarian veterans from WWII. In the years to follow the project expanded significantly and the team included many new members. By acquiring funding from the Center for Excellence in the Humanities “Alma Mater” the team managed to conduct a national-wide field work to gather oral history data from all the 28 administrative regions of Bulgaria in the course of a three years-long field work campaign. Thus, a collection of about 400 separate oral history interviews covering all regions of Bulgaria was formed. The collection includes representatives of almost all types of troops as well as members of almost all ethnic and confessional minorities if Bulgaria. A number of female veterans was also interviewed. In addition, the collection includes respondents with different social status as well as with various political affiliation. Thus, the members of the team tried to reflect the political diversity in Bulgaria during the war and to trace the influence of the opposing political views on the interpretation of key events from the period. Contrast were sought in particular among the members of the Communist party who made rapid social advancement after the war and members of opposition groups and parties (such as BZNS, BNL, etc.) who were often repressed in the years after the conflict.
During the last decade the team was concentrated on the field work given the advanced age of the respondents (currently about 96-97 years old) and the rapid decline in their numbers. Yet 39 selected interviews have been published in two consecutive volumes (2011 and 2015) and have been made accessible on the website of the research group: https://veterani.uni-sofia.bg/interviews; where the two volumes are also available.
Now the team faces the challenge to extract and interpret the information of a field work material that have been gathered for more than a decade. Such a huge quantity of data suggests the usage of Digital Humanities and the first steps towards the digitalization process have been made during the fieldwork. Thus, all the interviews are conducted and preserved in a digital form (mainly audio files, many pictures of the respondents, a number of photos from the period of the war, as well as few video records). The resulting database has been organized according to geographical principles and the interviews have been ordered according to the modern administrative division of Bulgaria, reflecting the place where the respondent lived at the moment of the interview. Yet the real challenge is how to apply the achievements of the Digital Humanities in the most time-consuming processes such as the transcription of the interviews as well as how to use the modern technologies for parallel analysis of the data, drawing of a social network of the respondents and the persons they mention, as well as mapping the individual fighting route of each veterans. The aim of the present paper is to present what has been achieved so far and to look for solutions of the technical problems faced by the team.
* : Corresponding author
Digital Humanities are experiencing a growing interest in Spain, especially in the last decade, becoming a leading trend in research, either as a field of study or as a preferential financing topic. At the same time, because of their novelty, they are under scrutiny by the research community and government institutions because the return of investment is not understood neither the role that Spanish researchers can play within European-wide research infrastructures, such as DARIAH.
In order to provide the global community of scholars working in this field with a greater understanding of the current Spanish scenario, LINHD has recently promoted an ongoing research on the evolution of Digital Humanities in Spain in the last 25 years, a timeframe comparable with Unsworth first formulation of scholarly primitives. The immediate goals of the study were to identify researchers in the field of Digital Humanities and to explore their financing, institutional affiliations, research projects and developed resources. The research has been very much data oriented and quantitative at its core, in order to quantify and describe initiatives, researchers, projects, digital resources, educational courses and scientific publications, connected among themselves and spanning from the nineties to the latest contributions. From a quantitative point of view, we collected bibliographical records from over 400 authors, that represent a good approximation of the available literature produced by researchers affiliated with Spanish institutions and a quantifiable measure of the impact and interest in DH within the Spanish research community in the Humanities. More than 360 projects have been mapped, generally small from the point of view of economic resources, but that together represent a significant amount of research funds dedicated, in the last twenty years and by a variety of public and private funding bodies, to research in this field (over 20 million euros). Finally, a dozen educational courses and over 80 digital resources of diverse nature (repositories of documents, collections of artefacts, crowdsourcing platforms, dictionaries, ...) have been analyzed, the latter, most of the time, produced with the aim to publish a service to improve the basic of day-to-day research in the Humanities.
In the context of this contribution, we plan to explore and exploit this relatively vast amount of data in order to identify how the introduction of digital tools and methods from Computer Science has affected the basic functions of research in the Humanities in Spain. Among the types of records collected, we believe that digital resources in particular will be able to provide insights, because they speak more about the reality of research workflows. To perform this analysis, resources will be classified and described according to classical scholarly primitives (discovering, annotating, comparing, referring, sampling, illustrating and representing), in order to highlight presences, absence and recurring associations of these categories, at certain specific stages and over time. Additionally, being resources already classified by discipline (Philology, History, Archaeology, History of Arts, ...) and typology, we will be able to visualize the relationships between scholarly primitives and other dimensions in our data. This taxonomy exercise will also provide an opportunity to reflect about the need for new possible classifications, and on how classical primitives can assume different meanings depending on the scope of a project.
* : Corresponding author
The poster aims to present the initiative to create a service that would integrate European bibliographical data in literary studies, starting from following countries: Czech Republic, Hungary, Poland, and Slovakia.
This initiative is led by the Czech and Polish Literary Bibliographies, and its development is one of the first activities of recently established DARIAH-ERIC Working Group “Bibliographical Data”.
The poster will address:
1) the motivation behind integrating bibliographical data,
2) challenges for development,
3) guiding principles of the service,
4) initiative's roadmap.
The goal of the poster is to gather interest from possible stakeholders (users, or data providers).
Motivation
Subject bibliographies are indispensable resources: they organize knowledge crucial to given discipline. As such they can serve as a reliable digital representation of knowledge production (and as such, for example, shape digitization policies), and become a basis for data-driven studies.
There are robust resources of open bibliodata: from specialized bibliographies with detailed subject description, through general library catalogues published under free licences, to metadata from scholarly repositories. Bibliodata researchers, and programmers can process them easily.
For literary studies bibliodata is fundamental: bibliodata serves not only as a source of information for further research, but it allows to perform data-driven studies on literary communication systems, book history, etc.
Sustainability: undoubtedly, integration of digital services in the humanities contributes to better sustainability, and systematically reduces interoperability issues for data-driven studies.
Main challenges
Understanding users' needs: in what way international bibliodata service might help scholarly community, especially when the cultural output is created in vernacular languages?
Data extraction, and processing: processing different metadata formats or even national/institution specific interpretations of general standards (e. g. MARC21), translating scope of bibliography into data extracting procedures, also from general bibliographies
Metadata alignment: aligning multilingual vocabularies, and different classification methodologies applied to create different bibliographical resources
Guiding principles:
1. Clearly defining, communicating, and documenting the scope and structure of published metadata,
2. Consistently providing data of both scholarly, and artistic nature - from books, journals, grey literature, and web resources, and different document types - articles, books, parts of the books, online content, etc.
3. High-quality and interoperable metadata that allows both for inter-cultural, international queries, and is consistent with FAIR principles, especially: crucial aspects of metadata are aligned internationally recognized controlled vocabularies (LCSH, LCGFT, COAR, VIAF, Geonames, etc.)
4. Community outreach: reaching out to the scholarly community, but also all those interested in literature by explaining the advantages of bibliodata integration.
Roadmap
First step:
- Integration of Czech and Polish - both scholarly, and artistic - literary bibliodata:
-
- 0,7 mln records from Polish Literary Bibliography, from 1989 to 2008, covering Polish literature and reception of foreign literatures in Poland,
- 0,6 mln records from Czech Literary Bibliography, from 1945 to 2020, covering Czech literature and its reception in the Czech Republic.
Next step:
- Scaling-up of the service - acquisitions of:
-
- data automatically retrieved from Polish printed bibliographical publications (1939-1988),
- data from the Retrospective Bibliography of Czech Literature (1770-1945)
- Hungarian, Slovakian literary bibliodata,
- CC0 bibliodata from European sources.
* : Corresponding author
The objective of this demo is to demonstrate the workflow, different analytical functions and features of the multilingual AVOBMAT (Analysis and Visualization of Bibliographic Metadata and Texts) data-driven digital tool, which has been developed by NLP researchers and a digital humanist since 2017. This web application enables digital humanists to critically analyse the bibliographic data and texts of large corpora and digital collections at scale. The unique features of the AVOBMAT toolkit are that (i) it combines state-of-the-art bibliographic data and computational text analysis research methods in one integrated, interactive and user-friendly web application; (ii) the implemented analytical and visualization tools provide interactive close and distant reading of texts and bibliographic data. It allows users to filter the uploaded datasets by metadata and full-text searches of various types and perform the bibliographic, network and NLP analyses on the filtered datasets.
In the preprocessing phase the user can set nine optional parameters such as lemmatization (spaCy, LemmaGen), context and stopword filtering. Users can create different configurations for the different analyses and visualizations. The metadata enrichment includes the automatic identification of the gender of the authors and automatic language detection of the documents.
Empowered by the Elasticsearch engine users can search and filter the uploaded and enriched bibliographic data and preprocessed texts in faceted, advanced and command line modes. AVOBMAT also supports fuzzy, proximity searches and regular expression queries.
Having filtered the uploaded databases and selected the metadata field(s) (107 in number), users can (i) analyze and visualize the bibliographic data chronologically in line and area charts in normalized and aggregated formats; (ii) create an interactive network analysis of maximum three (meta)data fields; (iii) make pie, horizontal and vertical bar charts of the bibliographic data of their choice according to the provided parameters.
As for the content analysis, the diachronic analysis of texts is supported by the N-gram viewer. The n-grams with a maximum 5-word length are generated at the preprocessing stage, along with the calculations of eight different lexical richness metrics.. Two special types of word cloud analyses are implemented: the significant text (Elasticsearch) cloud showing what differentiates a subset of the documents from others and the TagSpheres (Jänicke and Scheuermann, 2017) enabling users to investigate the context of a word. There are bar chart versions of the different word clouds that present the applied scores and frequencies. The traditional close reading examination is fostered by the TagSpheres and the Keyword in Context representations of the search queries.
AVOBMAT has an in-browser Latent Dirichlet Allocation function to calculate and visualize the topic models (e.g. time series, topic correlations). Besides setting the number of iterations and topics, it allows for the adjustment of the LDA alpha and beta hyperparameters.
The export functions of AVOBMAT facilitate the reproducibility of the results and transparency of the preprocessing and text analysis. It helps users realize the epistemological challenges, limitations and strengths of computational text analysis and visual representation of digital texts and datasets. AVOBMAT will be released in the second half of 2020.
1 : DARIAH-EU
OPERAS is a Research Infrastructure supporting open scholarly communication in the social sciences and humanities (SSH) in the European Research Area. Its mission is to coordinate and to federate resources in Europe to efficiently address the scholarly communication needs of European researchers in the field of SSH. OPERAS aim is to make Open Science a reality for research in the SSH. We want to achieve a scholarly communication system where knowledge produced in the SSH benefits researchers, academics, and students fully and widely, and where it also benefits the whole society across Europe and worldwide.
In doing so, OPERAS, also thanks to its services, aims at allowing use of the scholarly primitives, including discoverability, annotating or even comparing. Of course, the focus of OPERAS being on scholarly communication, not all scholarly primitives are planned to be covered here.
The discoverability service, being developed within the TRIPLE project and funded by the European Commission, will therefore serve as the discoverability platform of OPERAS and will be available to researchers in order to discover 3 main types of resources: data(sets), researchers' profiles, and projects – data here is mostly meant as publication data. By aligning the metadata retrieved from various sources (either harvested or retrieved via APIs) and enriching it (also with the help of machine learning), comparison will also be possible on the metadata level of the resources.
Also used not only by the researchers, but also useful for publishers and funders, the Metrics Service developed in the HIRMEOS project and now in beta, currently linked to 5 different partner platforms allows usage metrics to be retrieved by a central service and available to all via its API. These Metrics are usage data coming from various sources such as views or downloads on multiple platforms (i.e. Google Books, World Reader, etc...) as well as Altmetrics coming from mentions on other platforms such as Twitter, or the annotation platform hypothes.is.
A Publishing Service Portal is currently being implemented as part of the OPERAS-P project, also funded by the European Commission. This portal, which is partly based on an already developed prototype made by DARIAH within its Humanities at Scale project, will provide to SSH researchers a simple and single entry-point in order to reach the different publishing services provided by OPERAS and its members.
OPERAS Certification service, provided by the DOAB (Directory of Open Access Books) platform and developed within the HIRMEOS project, and already operational in beta, is intended to certify publishers at publishers' and at single publications' levels. The peer-review information is then available via a public API as well.
There are other services also available or being developed, but the focus will be done on those 4 developed or soon to be developed services. We will also present how the services will be brought and available to a larger community by reaching out when they are successfully available via the EOSC Marketplace.
* : Corresponding author
The construction of the portal Znameniti.hr started in 2016 with the aim of gathering and unified search of digital material of the leading figures of Croatian culture, science and art from various collections / repositories of Croatian cultural, artistic and scientific institutions. The purpose of the project was to develop a collaborative platform that would make non-commercial scientific, cultural and artistic digital content more accessible to researchers and the general public. Over time, partner institutions have established a collaborative model for portal development and maintenance, and through a variety of projects, work is being done to increase the scope and diversity of digital content represented, to develop new functionalities and to include various institutions that have valuable contributions in their digital collections / repositories about prominent figures of the Croatian past and present into the project.
The Znameniti Project is trying to keep up with the latest developments in the field of new technologies, especially in the field of digital humanities and trying to apply the latest technological advances that will make it more attractive to scientists and the wider user population. With the development of new technologies, especially GIS ( Geographical Information System ) space has become an important concept of the humanities. The application of GIS in the field of the humanities not only achieves the ordinary spatial mapping of geographical space, but a better understanding of the concept of place as a space with its own history and memory. This use of new technologies within the humanities leads to a new multidimensional and multidisciplinary approach called spatial humanities, whose main research focus has been deep mapping.
Spatial humanities, as a field of digital humanities, develops the assumption that the development of new technologies will allow multidimensional representation of space.. Such processes are called deep mapping precisely because of the possibility of multiperspectival exploration as well as deep connectivity at different spatial and temporal scales.
This paper focuses on prominent writers and the place / institution where digital content about them is represented. The aim of the paper is to give an account of the deep mapping of the place / institution where individual writers are stored. The mapping will attempt to cover all significant historical, cultural and social aspects that have influenced the development of individual institutions. The purpose is to raise awareness of the importance of the institution as a place where memory is being preserved, as well as to contribute to a better interpretation of the lives and activities of famous writers. This approach will try to determine in more detail in which places / institutions the digital content of individual writers is most represented, as well as the possible factors that may have influenced their representation in that institution. With deep mapping, place takes on a whole new dimension in the virtual environment and with all its significant historical, cultural and social characteristics, it greatly facilitates the availability of a wider range of information. With the deep mapping approach, the place takes an important role in the humanities as a source for various scientific research.
2 : Institute of Croatian Language and Linguistics (IHJJ)
* : Corresponding author
Retro-digitization of Croatian linguistic heritage is an important component of the Digital Humanities Network in Croatia, as an area of scholarly activity at the intersection of the computing or digital technologies and the disciplines of the humanities. Despite that, the creation of retro-digitized resources in Croatia is still in its beginnings and the existing resources do not include grammars from the pre-standard period of the Croatian language. Therefore, there is no repository that would contain a digitized and searchable database of Croatian language grammar books of the period, no model that could be applied and no systematically conducted scholarly research in the field. The aim of the project Retro-digitization and Interpretation of Croatian Grammar Books before Illyrism to change this situation.
This innovative (in the context of the European and Croatian philology) and comprehensive approach of presenting eight historical grammars implies the transfer of the printed media to computer-readable and searchable text. In this project, it also includes a multilevel mark-up of the transcribed or translated grammar text and its connection with facsimiles. Digitization process will include the mark-up of the grammar text segments and morphological paradigms by TEI tags and will be conducted on transcriptions or translations of the selected grammars. The way of grammar editing depends on the particularities of each grammar, as not all grammars are written in Croatian, nor all grammars describe the Croatian language.
The main aim of the project is to create a web portal of the Croatian grammar books before Illyrism (before the choice of the common standard language and orthography), which would include facsimiles of selected grammar books with basic information, transcription or translation and an index of historical grammar and linguistic terminology. The portal will be equipped with thematic searching possibilities on the morphology level.
This innovative and digital approach of presenting old texts (which are not always easily accessible) fundamentally changes the perspective and practicalities of conducting research on the historical material. Digital facsimiles will enable research on the material which was not presented before (some grammars are still in manuscripts) and the individual mark-up of the morphological paradigms will enable comparison between the selected grammars.
The web portal of early Croatian grammar handbooks will be open for the general public and will serve as an example of presenting historical texts of any kind and as a starting point of similar research in the different fields of humanities, and particularly historical linguistics. This kind of digital infrastructure is available for further upgrade and opens the possibility of linking and exchanging knowledge with other institutions.
This work has been fully supported by Croatian Science Foundation under the project Retro-digitization and Interpretation of Croatian Grammar Books before Illyrism IP-2018-01-3585. Research group: dr. Petra Bago, dr. Martina Kramarić, dr. Ivana Lovrić Jović, dr. Ana Mihaljević, dr. Sanja Perić Gavrančić, dr. Ivo Pranjković, dr. Diana Stolac, dr. Ljiljana Šarić, dr. Barbara Štebih Golub, dr. Tamara Tvrtković. The project leader: dr. Marijana Horvat.
* : Corresponding author
The main purpose of this poster is to present the importance of retroconversion of bibliographical documents which are crucial in data-driven research activities in areas such as literary research, cultural and art studies.
What is retroconversion of bibliographical publications?
Retroconversion understood as transformation process of printed bibliographical publications into human- and machine-readable database can be also enriched with such elements as linked open data and semantic web mechanisms which can create a unique, modern and rich source of information about knowledge production in various research domains, which translates both into facilitating scientific research and also into creation of new research areas and topics.
Main goals and challenges
In particular, the poster will present the following challenges/goals:
- challenges of transforming varied bibliographical elements from different sources and periods into one, structured and consistent database,
- advantages of creating open and structured bibliographical database,
- integrating bibliographical metadata with other, similar solutions in different research fields and countries,
benefits of enriching converted metadata by additional informations and links to external sources.
The main purpose of the poster is to draw the attention of scientists and academic and research units to the issue of access to bibliographic data.
Research project info
The poster will be based on findings of PhD research project Retroconversion of Polish Literary Bibliography which is being prepared at the Institute of Literary Research of the Polish Academy of Sciences (IBL PAN) and Polish-Japanese Academy of Information Technology (Digital Humanities postgraduate studies), in cooperation with Department of Current Bibliography of the IBL PAN.
Project is focused on transforming Polish Literary Bibliography (https://pbl.ibl.waw.pl/) - which is one of the most important sources of information about Polish literature and culture in Poland - into structured and linked database using a number of algorithms and machine learning solutions.
Project of retroconversion of Polish Literary Bibliography is also supported by DARIAH-ERIC Working Group “Bibliographical Data”.
* : Corresponding author
The main focus of the PROVIDEDH project is geared toward the creation of visualization systems that aid in the handling of uncertainty in Digital Humanities (DH) datasets. Our tools on the collaborative platform were developed against the background of human-centered design with a focus on easing uncertainty annotation and visualization, promoting the use of TEI standards and making uncertainty play a more active role in the research process.
At the moment our platform allows users to create research projects, upload batches of TEI files, annotate these files concurrently by multiple users as well as identify and manage the entities appearing in the files. Users are able to create their own taxonomies of uncertainty or use a default one to make annotations. All annotations and unifications made on the platform can be rendered then to the TEI format. The user does not need to be familiar with TEI, as our platform provides him/her a friendly interface for annotating electronic texts. This allows a variety of users to use a platform in ways suitable to their various needs and datasets.
We are currently working on visualising existing links between entities in different project files, and providing visual tools for analysing uncertainty, its sources, meaning, and context. Those visualisations should allow users to interact with data in a more intuitive way and see more clearly the connections, trends and anomalies.
In addition to functionalities explained above, enabling users to manually make decisions about the dataset, we plan to incorporate into the platform the Decision Support Subsystem (DSS), which should suggest users actions to be taken with regard to project data. Despite it is planned to support many different exploration scenarios in the future, the system is first showcased to support a typical DH task: entity normalization. In this regard, the system employs a neural network and a weighted multigraphs to automatically recognize entities appearing in the TEI files under different identifiers and to suggest unifications when certain similarities in the input data (connections between nodes in the graph) are detected. In this graph, the nodes (representing entities in the system) are connected by edges constructed and weighted by metadata analysis. For example, the data to be analysed may consist of, inter alia, gender, dates, mentions' context, geodata derived from place names or mutual acquaintances. The intermediate edge-weighting step allows adjusting the impact of different types of connections between the entities in an interactive manner. Additionally, the algorithm learns from users' actions on the same and other datasets. All this information is progressively presented to the user to inform the decision-making in the normalization task. The aim of this presentation is to familiarize attendees with the current capabilities of the platform, and the development roadmap of the platform until the end of the project. During the conference, we expect to gather important feedback from the DH community in order to advance the state-of-the-art in novel and useful ways in the future.
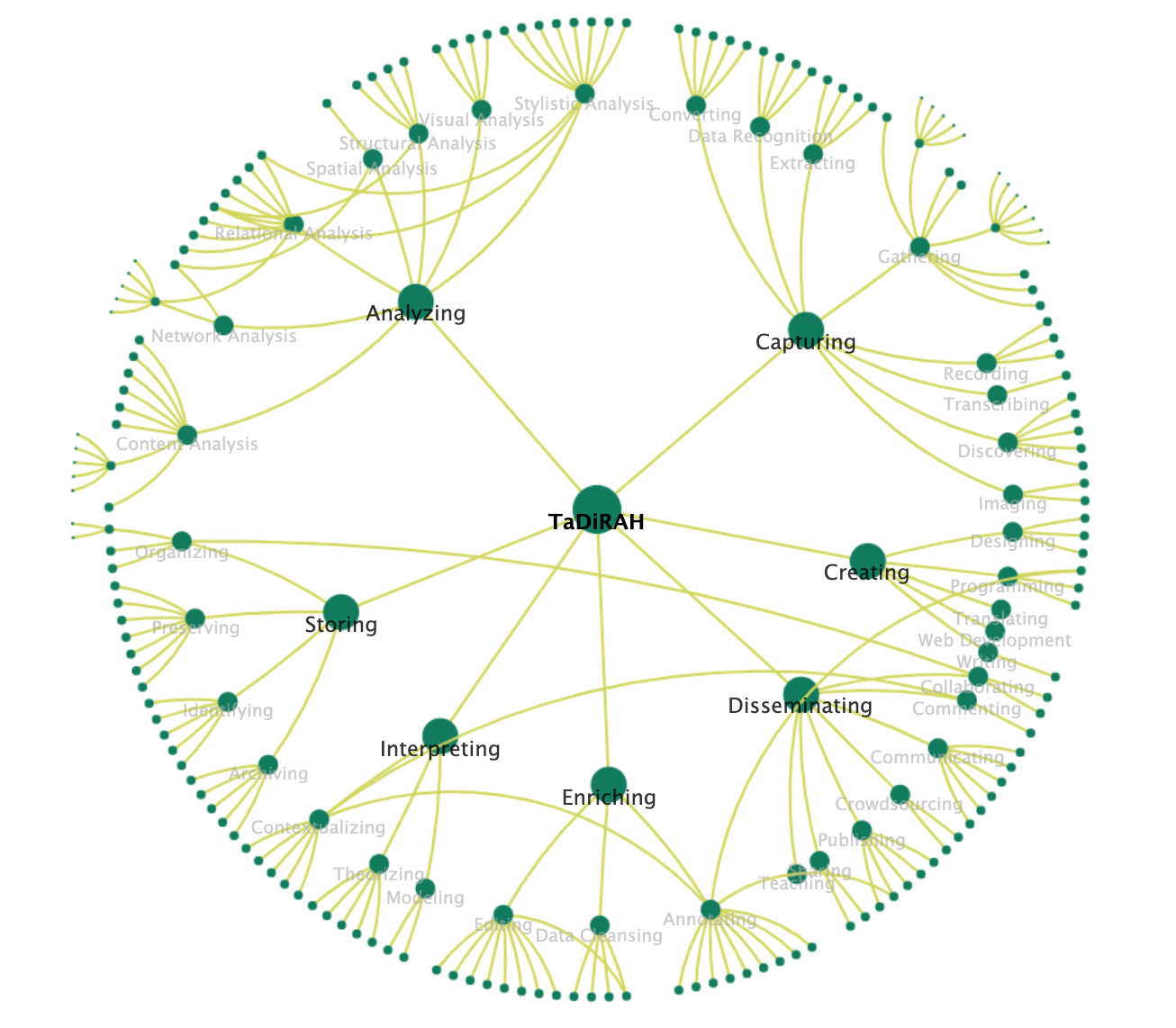
Classifying and categorizing the activities that comprise the Digital Humanities (DH) has been a longstanding area of interest for many practitioners in this field, fueled by ongoing attempts to define Digital Humanities both within the academic and public sphere. The emergence of directories that cross traditional disciplinary boundaries has also spurred interest in categorization, with the practical goal of helping scholars identify, for instance, projects that take a similar technical approach, even if their subject matter and objects are vastly different.
TaDiRAH, the Taxonomy of Digital Research Activities in the Humanities, is the result of a year-long project undertaken by the DiRT (Digital Research Tools) Directory and DARIAH-DE (Digital Research Infrastructure for the Arts and Humanities) to develop a shared taxonomy. TaDIRAH was created to organize the content of sites as diverse as the DARIAH Zotero bibliography ‘Doing Digital Humanities', the DHCommons online hub and DiRT (now TAPoR, the Text Analysis Portal for Research). It has also been used with the Standardization Survival Kit research use case scenario collection, and AGATE, a European Science Academies Gateway for the Humanities and Social Sciences, to name just a few examples.
TaDiRAH has been shaped both by and for the DH community to classify and define research activities in the humanities and related fields. With DHCommons, DARIAH and Europeana as its original use case environments, it has developed into a widely known taxonomy that has been used and adapted in various international research projects. Through a community-driven approach, TaDiRAH has been improved through user feedback and has been translated into French, German, Spanish and Serbian increasing its application. However, to meet an increasing demand that is intensified by the growing influence of linked data technologies ensuring interoperability in digital research infrastructures, TaDiRAH should now evolve from a sum of terms in the form of narrower and broader relationships to a formalized model with a common ontological basis. Within CLARIAH-DE the taxonomy is now translated into a machine-readable version in order to implement it in the Language Resource Switchboard (LRS).This process includes the conceptualization, semantification and formalization of the existing taxonomy in terms of the FAIR Principles.It will be made available as Simple Knowledge Organization System (SKOS) including a SPARQL endpoint becoming part of DARIAH-EU's Vocabs services hosted at the Austrian Centre for Digital Humanities Austrian Academy of Sciences (ACDH-ÖAW).
TaDiRAH's aim remains to be a community-driven taxonomy that is easy to use and meets the needs of a wide variety of humanities scholars. The goal, therefore, is to provide a version that is more fully compliant with standards for Linked Open Data (LOD). With several European initiatives currently shaping advanced research infrastructures that could benefit from its implementation, new collaborations have been formed to bring TaDiRAH to this next level. TaDiRAH's implementation may lead to the taxonomy living on and help categorize, visualize, search, and find the activities and results of Digital Humanities initiatives.
2 : Institute of Computer Science (ICS-FORTH)
The Backbone Thesaurus (BBT for short) [1] is the research outcome of work undertaken by the Thesaurus Maintenance WG in an effort to design and establish a coherent overarching meta-thesaurus for the Humanities, under which specialist thesauri and structured vocabularies used across scholarly communities can be integrated and form a thesaurus federation. Its core feature is that it promotes alignment of cutting-edge terminology to the well-formed terms of the meta-thesaurus capturing general meanings. The BBT favors a loose integration of multiple thesauri, by offering a small set of top-level concepts (facets and hierarchies) for specialist thesauri terms to map to. This way, it enables cross-disciplinary resource discovery, while ensuring compatibility with thesauri that cover highly specific scientific domains and areas of knowledge in development.
The labels and the definitions for the facets and hierarchies of the BBT are available in four (4) languages –namely, English, French, German, and Greek.
The controlled vocabularies/thesauri the concepts of which have been mapped to the BBT to this date are the DAI Thesaurus [2], the DYAS Humanities Thesaurus [3] and the Parthenos Vocabularies [4]. At the same time, members of the working group are working towards integrating the Language of Bindings Thesaurus [5], PACTOLS [6], the Taxonomy of Digital Research Activities in the Humanities (TADiRAH) [7] and the Arts and Architecture Thesaurus [7] with the BBT, at least partially.
The BBT is systematically curated by a cross disciplinary team of editors coming from organizations participating in the TMWG (AA, DAI, FORTH, FRANTIQ/CNRS), through BBTalk [8], an online service designed to support collaborative, interdisciplinary development and extension of thesauri. The BBT versions are regularly uploaded to the DARIAH-EU vocabularies along with all their connections to local thesauri via the ACDH-ÖAW service [9].
Goal of this presentation is to showcase the benefits of joining the BBT federation and become part a gradually growing community of thesauri maintainers. The Thesaurus Maintenance WG will bring forward in a YouTube video linked on a poster via a QR code, designed for the Marketplace of the 2020 Annual Event, the cases of DAI and FRANTIQ. Their experience will help outline the challenges encountered in the curatorial process and how they were solved. We envisage that this presentation will serve as an overall evaluation of the work performed thus far by the Thesaurus Maintenance WG.
References
[1] https://www.backbonethesaurus.eu
[2] http://thesauri.dainst.org/de/labels/_f04f41ba.html
[3] https://humanitiesthesaurus.academyofathens.gr/
[4] https://isl.ics.forth.gr/parthenos_vocabularies/
[5] https://www.ligatus.org.uk/lob/
[6] https://pactols.frantiq.fr/opentheso/
[7] http://tadirah.dariah.eu/vocab/
[8] www.backbonethesaurus.eu/BBTalk
[9] https://vocabs.dariah.eu/backbone_thesaurus/en
Current Main Editors: Martin Doerr, Gerasimos Chrysovitsanos, Helen Goulis, Helen Katsiadakis, Patricia Kalafata, Yorgos Tzedopoulos, Blandine Nouvel, Evelyne Sinigaglia, Camilla Colombi, Lena Vitt, Chrysoula Bekiari, Eleni Tsoulouha, George Bruseker, Lida Harami. DARIAH Backbone Thesaurus (BBT): Definition of a model for sustainable interoperable thesauri maintenance, Version 1.2.2, May 2019 (https://www.backbonethesaurus.eu/sites/default/files/DARIAH_BBT%20v%201.2.2%20draft%20v1.pdf)
M.Daskalaki, L. Charami, 2017, A Back Bone Thesaurus for Digital Humanities, ERCIM News 111, October 2017, Special theme: Digital Humanities (https://www.backbonethesaurus.eu/sites/default/files/A%20Back%20Bone%20Thesaurus%20for%20Digital%20Humanities.pdf)
M. Daskalaki, M. Doerr, 2017, Philosophical background assumptions in digitized knowledge representation systems, in Dia-noesis: A Journal of Philosophy, 2017, Issue 3, p 17-28. (https://www.backbonethesaurus.eu/sites/default/files/Philosophical%20background%20assumptions.pdf)
Christos Georgis, George Bruseker and Eleni Tsouloucha, 2019, BBTalk: An Online Service for Collaborative and Transparent Thesaurus Curation, ERCIM News 116, January 2019 (https://www.backbonethesaurus.eu/sites/default/files/BBTalk%20%28ERCIM-News-116%29.pdf)
Watch the BBT User Stories here: https://youtu.be/QdDEGN-jiRY
2 : University of Graz (Uni Graz)
3 : Institute of Ethnology and Folklore Research (IEF)
* : Corresponding author
In this poster and demo, we would like to introduce the “consent form wizard” developed by the DARIAH-EU working group “Ethics and Legality in Digital Arts and Humanities” (ELDAH).
This tool is currently under development and will be finalized and available in time for the DARIAH annual meeting. It will enable digital scholars as well as the wider research infrastructure community to quickly and easily obtain a standardized consent form that is conforming to the obligations and regulations of the European Union General Data Protection regulation (GDPR) and therefore legally valid in all of the European Union.
Depending on the context for which consent is obtained (e.g. use of images of people at academic events, processing of information shared in surveys, collection / processing of personal data), the wizard users will receive a consent form tailored to their specific needs after answering a series of questions. The different scenarios are the result of discussions with participants of the DH2019 in Utrecht and the DARIAH Annual Meeting 2019 in Warsaw and hence driven by the needs of the research community. Additional meetings with stakeholders from cultural heritage organisations (e.g. ICARUS) and the DARIAH-EU community will ensure a critical evaluation as well as a pragmatic, user-friendly implementation of the tool.
It will build on the code of the CLARIN LINDAT Public License Selector which offers the same service for license selection that we would like to develop for obtaining a consent form. Software developers, legal experts and (digital) humanities researchers will cooperate in the development of this tool, which - while legally addressing the strict data protection regulations of the European Union - will also be of use for the international research community outside Europe, since the consent forms will provide a best-practice template for ethical research conduct when processing personal data, and hence address the increasingly prominent topic of ethical research practice and scientific behaviour, especially in a largely digital, internet-based research context.
The presentation of this poster and demo at the DARIAH annual event will allow us to present the wizard to our infrastructures colleagues, discuss their needs and experiences with the protection of personal data and hence, if appropriate, adapt the wizard to reflect the European common perspective on research ethics and the processing of personal data.
General Data Protection Regulation (GDPR)
International Centre for Archival Research
Kamocki, Paweł, Pavel Stranák, and Michal Sedlák. “The Public License Selector: Making Open Licensing Easier.” Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC 2016), Portorož, Slovenia, edited by Nicoletta Calzolari, Khalid Choukri, Thierry Declerck, Sara Goggi, Marko Grobelnik, Bente Maegaard, et al., 2533–2538. Paris: European Language Resources Association (ELRA), 2016. http://www.lrec-conf.org/proceedings/lrec2016/pdf/880_Paper.pdf
* : Corresponding author
The project “The database of antique archaeological sites of the Republic of Croatia” is outgoing project of the Institute of Archeology and it is set on website of the Institute (http://baza.iarh.hr/public/locality/map).
We intend to present an outgoing project; explain what is “The database of antique archaeological sites” and what information can be find in this base.
The Database (BAZA) uses as its foundation the wealth of Croatian archeological sites. It was created in order to structure the data collected during the work of the Institute. As a source of data, the available literature is used together with knowledge gathered from the Institute's scientific activities and data stored in the archives of the Institute of Archeology. The aim of the project is creating a database of Greek and Roman archaeological sites as the foundation for science, culture, preservation of Croatian heritage, as well as the presentation of cultural tourism. In addition, goals is to educate people about the historical importance of the area, its heritage and to draw attention at the long-abandoned and forgotten sites.
The DATABASE is based on archeological sites in Croatia that are known in the literature or established through field research with the aim of creating a tool that provide easier access to data needed for future scientific research, heritage management, and the creation of professional and scientific projects that have archeological basis heritage.
The database is enriched with information on archeological sites that are attractive enough to become a tourist destination. Data availability enables business, scientific and private entities from Croatia as well as around the world to access information about the desired cultural archaeological destination.
Over the last few years, a research object has been attracting the attention of quite a number of members of the scientific community of digital humanities and sociology: the study of algorithms, and more precisely of their impact on society. Examples include the study of the impact of work distribution algorithms (Uber), recidivism prediction algorithms (COMPAS) or recommendation algorithms (Youtube or Spotify). Both quantitative and qualitative methods are used for these studies. At the same time, we can find an increasing integration of the digital humanities in these studies, both to analyse the data used by the algorithms and their results. To a more limited extent, simulations of the operation of these algorithms can be found.
However, and this is the purpose of this poster, an insufficient number of studies in this field have focused on the fabrication of these algorithms, either on the way engineers and more widely organizations design these programs that have the impacts that we now know a little better (their non-neutrality or discrimination to name only two).
Sociologists can study this fabrication by using qualitative methods by interviewing designers or by conducting immersion studies in the companies which develop these algorithms. Quantitative methods are, to our knowledge, not very relevant (the chances of accessing a critical mass of data are low). On their side, the digital humanities have initially brought methods or reverse engineering solutions, i.e. attempts to open the black box and understand how the algorithm works technically.
As co-author of a sociological study being finalized on the design of recommendation algorithms based on thirty interviews, I would like to present the following two challenges with a poster exhibited at the DARIAH Annual Event 2020. The first stake is to give a new perspective to the work on the ethical issues raised by algorithms. The analysis of the responses of the 30 engineers provides a rich portrait of their apprehension of work, particularly through the dichotomy between "high ideals" (such as educating citizens) and "low ideals" (such as optimising a particular variable).
The second major challenge is to propose ways in which the digital humanities and sociology could collaborate to study the making of algorithms that would go beyond the use of tools to analyze and categorize interview material. The whole point here is to launch a reflection to find a relevant and innovative method allowing the global study of algorithms, from their (theoretical) conception to their impacts, going through their fabrication and their use, in order to expand the production of knowledge. The process of analyzing the interviews on the recommendation algorithms design and the study's writing should allow to bring the first elements of answer, to open the discussion and to revisit the seven scholarly primitives.